大数据面试必问 数据存储利器HBase及其数据处理与存储支持服务
在大数据技术领域,HBase作为一款高可靠性、高性能、面向列、可伸缩的分布式存储系统,无疑是面试中的高频考点。它不仅是Hadoop生态系统中的重要成员,更是处理海量结构化与非结构化数据的核心利器。本文将从HBase的核心特性、数据处理能力以及其背后的存储支持服务三个维度进行解析,助你从容应对面试挑战。
一、HBase的核心特性:为何成为存储利器?
- 列式存储与稀疏性:与传统关系型数据库的行式存储不同,HBase采用列族(Column Family)进行数据组织。这种结构特别适合稀疏数据,空值不占用存储空间,极大地提升了存储效率,非常适用于互联网场景下多变的业务数据模型。
- 强一致性与高可用性:基于HDFS的多副本机制,并通过RegionServer和ZooKeeper的协同,HBase保证了数据的强一致性和服务的高可用性。单个节点故障不会导致数据丢失或服务中断,这是其作为关键数据存储的基石。
- 极强的可扩展性:通过简单地增加RegionServer节点,即可实现存储容量和读写吞吐量的线性扩展,能够轻松应对从GB到PB级别的数据增长,满足大数据时代的海量存储需求。
- 高效的随机读写:HBase通过LSM-Tree(Log-Structured Merge-Tree)数据结构、MemStore内存写缓存和Bloom Filter等机制,在保证持久化的提供了卓越的随机实时读写性能,弥补了HDFS仅擅长顺序批处理的不足。
二、HBase的数据处理能力:如何驾驭海量数据?
面试官常关注候选人如何利用HBase进行实际的数据操作与处理。
- 核心数据操作API:
- Put:用于插入或更新数据。面试中需理解其原子性(行级)及时间戳版本控制机制。
- Get:基于RowKey的单行随机读取,强调其高效性源于RowKey的有序存储设计。
- Scan:范围扫描,是进行全表或部分数据查询的关键。性能优化点在于设置合理的StartRow和StopRow,避免全表扫描。
- Delete:标记删除而非物理立即删除,通过Major Compaction最终清理。需理解其多版本下的删除逻辑。
- 与MapReduce/Spark的集成:HBase作为数据源(TableInputFormat)或数据汇(TableOutputFormat),能够无缝对接Hadoop MapReduce或Apache Spark进行分布式批量计算,实现复杂的数据处理与分析。
- 协处理器(Coprocessor):这是高级特性,分为Observer(类似触发器,用于在数据操作前后执行自定义逻辑)和Endpoint(类似存储过程,用于在服务端执行聚合计算)。它允许将计算逻辑推送到数据所在服务器,减少网络传输,极大提升处理效率。
三、支撑HBase运行的存储支持服务
理解其底层依赖的服务,能体现对系统架构的深度认知。
1. HDFS:持久化存储层
HBase的所有数据文件(HFile)最终存储在HDFS上。HDFS提供了高吞吐量的顺序读写能力和可靠的多副本冗余,是HBase海量、持久化存储的根基。面试需明确HBase与HDFS的分工:HBase负责数据的管理与随机访问,HDFS负责数据的底层分布式存储。
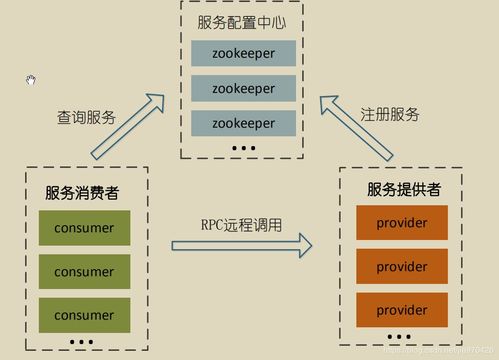
2. ZooKeeper:分布式协调服务
ZooKeeper在HBase架构中扮演着“中枢神经”的角色,主要负责:
- 维护集群的元数据,如根Region(meta表)的位置。
- 监控RegionServer的状态,实现故障转移(Failover)。
- 提供分布式锁等协调机制,保障Master选举、Region分配等操作的唯一性与一致性。
可以说,没有ZooKeeper,HBase集群就无法正常启动和协调工作。
面试要点
- RowKey设计:这是HBase应用的灵魂。需掌握设计原则(如散列性、有序性、长度适中),并能够举例说明(如反转时间戳、加盐等)以解决热点问题。
- 读写流程:能清晰描述一次读写请求如何经过ZooKeeper、Client、RegionServer、MemStore、HLog(WAL)、HDFS的协同完成。
- Compaction机制:理解Minor Compaction和Major Compaction的作用(合并文件、清理过期数据),及其对读写性能的影响(权衡I/O与空间)。
- 应用场景:能准确说出HBase的典型应用场景,如实时消息/日志存储、用户画像、交易记录查询、物联网时序数据等,并与HDFS、Kafka、关系型数据库进行对比。
总而言之,深入理解HBase作为“数据存储利器”的特性、数据处理方式及其与HDFS、ZooKeeper等支持服务的协同,能够帮助你在面试中展现出扎实的技术功底和清晰的架构思维,从而脱颖而出。
如若转载,请注明出处:http://www.ftqimeisi.com/product/73.html
更新时间:2026-02-27 07:39:56