Java内存管理详解 数据处理与存储背后的高效支持服务
Java作为一门广泛应用于企业级开发、大数据处理和云原生服务的编程语言,其强大的内存管理机制是支撑复杂数据处理与高效存储服务的核心。理解Java内存模型、垃圾回收机制以及相关优化策略,对于构建高性能、高可靠的数据处理系统至关重要。本文将从基础概念出发,结合数据处理与存储的典型场景,深入解析Java内存管理的原理与实践。
一、Java内存区域划分:数据处理的舞台
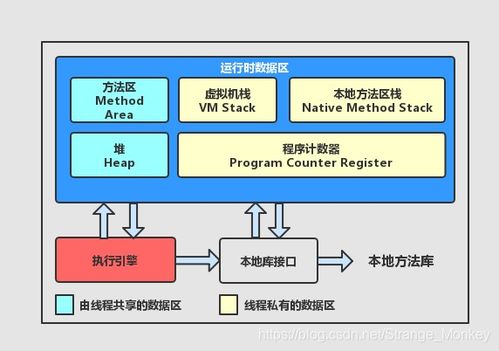
Java虚拟机(JVM)将运行时数据区域划分为多个部分,每个部分承担着不同的职责,共同协作以支持数据的处理与暂存。
- 程序计数器:当前线程所执行的字节码的行号指示器,是线程私有的,确保多线程环境下数据处理任务能正确切换。
- Java虚拟机栈:同样线程私有,生命周期与线程相同。每个方法执行时会创建一个栈帧,用于存储局部变量表、操作数栈、动态链接和方法出口等信息。这是方法调用和局部变量(包括基本数据类型和对象引用)处理的直接场所。
- 本地方法栈:为JVM调用本地(Native)方法服务。
- Java堆:这是内存管理的核心区域,也是数据处理与存储服务中最活跃的部分。所有对象实例和数组都在堆上分配内存。堆是被所有线程共享的,因此也是垃圾回收器管理的主要区域。根据对象存活周期,现代垃圾回收器通常将堆进一步细分为:
- 新生代(Young Generation):存放新创建的对象。绝大多数数据处理过程中产生的临时对象、中间结果在这里经历“朝生夕死”。它又分为Eden区和两个Survivor区(S0, S1)。
- 老年代(Old Generation):存放经过多次垃圾回收依然存活的对象,以及一些大对象(如大的数据缓存、数据库连接池对象等)。这些通常是核心的业务数据对象或长期存储的元数据。
- 元空间(Metaspace, JDK8+) / 永久代(PermGen, JDK7-):用于存储类的元数据信息,如类名、方法名、字段名、常量池等。对于需要动态加载大量类的数据处理框架(如Spark、Flink)或应用服务器,此区域的管理也至关重要。
- 方法区:用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码缓存等。可以看作是元空间/永久代的概念性描述。
二、垃圾回收机制:自动化的存储空间清理服务
Java的自动垃圾回收(GC)是其内存管理的一大优势,它像一位高效的“数据保洁员”,自动回收不再使用的对象所占用的堆内存,防止内存泄漏,保障数据处理服务的持续稳定运行。
- 对象存活的判定:
- 引用计数法(Java未主流采用):简单但无法解决循环引用问题。
- 可达性分析算法:通过一系列称为“GC Roots”的根对象(如虚拟机栈中的引用、静态属性引用的对象、常量引用的对象等)作为起点,向下搜索,所走过的路径称为引用链。如果一个对象到GC Roots没有任何引用链相连,则判定为可回收。这是JVM主流算法。
- 经典垃圾回收算法:
- 标记-清除:先标记所有需要回收的对象,然后统一回收。简单但会产生内存碎片。
- 复制:将内存分为两块,每次只使用一块。垃圾回收时,将存活对象复制到另一块,然后清空已使用块。高效无碎片,但内存利用率仅50%。新生代的Survivor区采用此算法的变体。
- 标记-整理:标记过程同“标记-清除”,但后续让所有存活对象向一端移动,然后直接清理掉边界以外的内存。老年代通常采用此算法或变体。
3. 分代收集理论与主流GC器:
JVM基于“弱分代假说”(绝大多数对象朝生夕死)和“强分代假说”(熬过越多次GC的对象越难消亡),采用了分代收集策略。
- 针对新生代:通常发生Minor GC,速度非常快。Serial, ParNew, Parallel Scavenge等收集器在此区域工作。
- 针对老年代:通常发生Major GC / Full GC(会连带触发新生代GC),速度较慢,停顿时间(STW)长。CMS, G1, ZGC, Shenandoah等收集器致力于降低此停顿。
- G1收集器:将堆划分为多个大小相等的独立区域(Region),可以面向任何区域进行收集。它能预测停顿时间,在延迟敏感的数据处理服务(如实时流处理)中应用广泛。
- 低延迟GC器(ZGC, Shenandoah):通过染色指针、读屏障等先进技术,将STW时间控制在毫秒甚至亚毫秒级别,非常适合对响应时间要求极高的在线数据服务。
三、面向数据处理与存储服务的优化实践
- 合理设置堆大小:通过
-Xms(初始堆大小)和-Xmx(最大堆大小)参数设置。对于大数据批处理作业,可以设置较大且相等的值以避免运行时扩容带来的性能抖动;对于需要快速响应的在线服务,需根据负载精细调整,避免过大导致GC停顿过长。 - 选择与调优GC器:
- 高吞吐量优先(如离线数据分析):
-XX:+UseParallelGC(Parallel Scavenge + Parallel Old)。
- 低延迟优先(如实时推荐、交易系统):
-XX:+UseG1GC,-XX:+UseZGC或-XX:+UseShenandoahGC,并配合相应调优参数(如目标最大停顿时间-XX:MaxGCPauseMillis)。
- 监控与诊断:利用JVM工具(如jstat, jmap, VisualVM, JMC)或APM工具监控堆内存使用情况、GC频率与耗时。重点关注Full GC的发生,这通常是性能瓶颈或内存泄漏的信号。
- 编码层面的优化:
- 避免内存泄漏:及时释放数据库连接、文件流、网络连接等资源;谨慎使用静态集合,注意对象的生命周期。
- 优化对象创建:复用对象(如使用对象池)、避免在循环体内创建大量临时对象、优先使用基本数据类型而非包装类。
- 合理使用缓存:对于热点数据,使用堆外缓存(如Ehcache、Caffeine)或分布式缓存(如Redis)来减轻堆压力,但需注意缓存淘汰策略和一致性。
- 针对大数据的特殊处理:在处理海量数据时,考虑使用堆外内存(如通过
ByteBuffer.allocateDirect或Netty的PooledByteBufAllocator)来存储数据,避免频繁的GC,或使用Spark/Flink等框架提供的托管内存机制。
###
Java的内存管理是一个庞大而精密的“支持服务系统”。从堆栈划分到分代回收,从GC算法到低延迟优化,每一个环节都深刻影响着数据处理与存储服务的性能、稳定性和扩展性。深入理解其原理,并结合实际业务场景进行监控、调优与编码实践,是每一位后端及数据平台开发者构建高效可靠系统的必修课。在云原生与实时计算的时代,掌握好内存管理这门艺术,能让你的数据服务在效率和成本之间找到最佳平衡点。
如若转载,请注明出处:http://www.ftqimeisi.com/product/71.html
更新时间:2026-02-27 10:48:24