专访QQ大数据团队 分布式计算系统开发与数据处理存储支持服务
随着互联网数据的指数级增长,分布式计算系统已成为现代数据处理架构的核心支柱。近日,我们有幸专访了QQ大数据团队,围绕其分布式计算系统开发实践、数据处理及存储支持服务进行了深度交流。
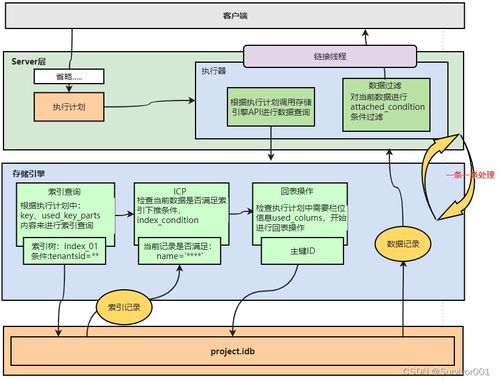
作为腾讯旗下重要产品的支撑力量,QQ大数据团队见证了海量用户行为的处理需求——从亿级用户的在线状态同步,到聊天记录的实时分析与历史查询,再到个性化推荐与安全风控。团队负责人李明指出:『我们的系统每日处理PB级数据,需确保毫秒级响应与99.99%的可用性。这背后是一套自研的分布式计算框架「QQDataFlow」,支持流批一体计算,并深度整合了机器学习管道。』
在数据处理层面,团队通过分层架构实现高效治理:原始数据经 Kafka 集群接入后,由 Flink 进行实时清洗与聚合;批处理任务则通过 Spark 执行复杂指标计算。值得注意的是,团队创新性地引入了「动态资源调度算法」,能根据业务峰谷自动调整计算节点,资源利用率提升40%。数据工程师王华补充:『我们为内部业务提供了统一数据服务门户,支持SQL即席查询与可视化报表生成,将数据分析门槛降至极低。』
存储体系的搭建同样彰显匠心。团队采用混合存储策略——热数据存于自研分布式数据库 TDSQL,冷数据归档至腾讯云对象存储。存储专家张磊详解其设计哲学:『我们为消息记录设计了冷热分离索引,热数据保证亚秒级查询,同时通过压缩算法将冷数据存储成本降低70%。所有存储节点均实现跨地域容灾,数据持久性达99.9999999999%。』
谈及未来规划,团队正聚焦三大方向:其一是推进计算存储分离架构,实现更极致的弹性扩缩容;其二是构建智能数据湖,打通业务孤岛并强化数据血缘追溯;其三是探索联邦学习在隐私保护场景的应用,让数据『可用不可见』。李明总结道:『分布式系统的本质是平衡艺术——在性能、成本与易用性间寻找最优解。我们将持续开放技术能力,为行业提供可复用的数据处理范式。』
这场专访揭示了一个真理:在数据洪流的时代,唯有将分布式技术与业务洞察深度融合,方能为用户创造流畅如水的数字体验。QQ大数据团队的实践,正为行业树立着技术赋能业务的鲜活样本。
如若转载,请注明出处:http://www.ftqimeisi.com/product/25.html
更新时间:2025-11-29 18:14:52