亿级数据湖统一存储技术实践
随着企业数据量的指数级增长,传统的分散式数据存储架构已难以满足大规模数据处理与分析的需求。亿级数据湖统一存储技术应运而生,旨在构建一个集中式、可扩展且统一的数据存储平台,以支持多样化的数据处理任务。本文将探讨亿级数据湖的技术实践,并重点介绍数据处理和存储支持服务的关键方面。
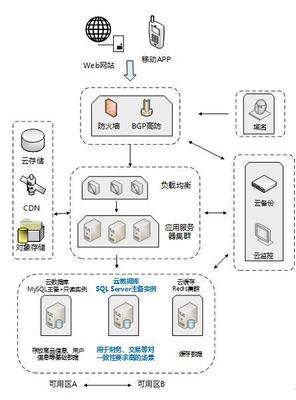
亿级数据湖的核心在于统一存储架构。通过采用对象存储(如Amazon S3、阿里云OSS)或分布式文件系统(如HDFS),数据湖能够整合结构化和非结构化数据,打破数据孤岛。这种架构支持PB级甚至EB级数据的存储,同时通过元数据管理实现数据的可发现性和治理。在实践中,企业需设计灵活的数据分区和索引策略,例如按日期、业务域或数据类型进行组织,以优化查询性能。结合数据压缩和分层存储(如热、温、冷数据分层),可以有效控制存储成本,确保高性价比的扩展性。
数据处理是数据湖生态的关键环节。借助大数据处理框架如Apache Spark、Flink或Hadoop,数据湖支持批处理和实时流处理,实现从原始数据到洞察的快速转换。在实践中,企业可以采用ETL(提取、转换、加载)或ELT(提取、加载、转换)流程,将数据清洗、转换和聚合任务整合到数据湖中。例如,通过Spark作业处理海量日志数据,生成聚合指标,或使用Flink进行实时事件处理,以支持即时决策。为了提升效率,数据湖常集成数据目录工具(如Apache Atlas)和数据质量监控机制,确保数据的一致性和可靠性。
存储支持服务则涵盖数据安全、备份和访问控制等方面。在亿级数据湖中,数据安全至关重要,需实施加密(如AES-256)、访问策略(如基于角色的访问控制)和审计日志,防止未授权访问和数据泄露。同时,定期备份和灾难恢复计划(如多区域复制)可保障数据的高可用性。存储支持服务还包括性能优化,例如通过缓存机制(如Alluxio)加速数据读取,或利用数据湖查询引擎(如Presto、Trino)提升交互式分析速度。
亿级数据湖统一存储技术实践不仅依赖于先进的存储架构和数据处理工具,还需要全面的支持服务来确保数据的安全性、可靠性和高效性。通过合理设计和管理,企业可以构建一个强大的数据基础,驱动业务创新和智能化转型。未来,随着AI和云原生技术的发展,数据湖将进一步演进,提供更智能的数据管理和自动化服务。
如若转载,请注明出处:http://www.ftqimeisi.com/product/33.html
更新时间:2025-11-29 02:12:16